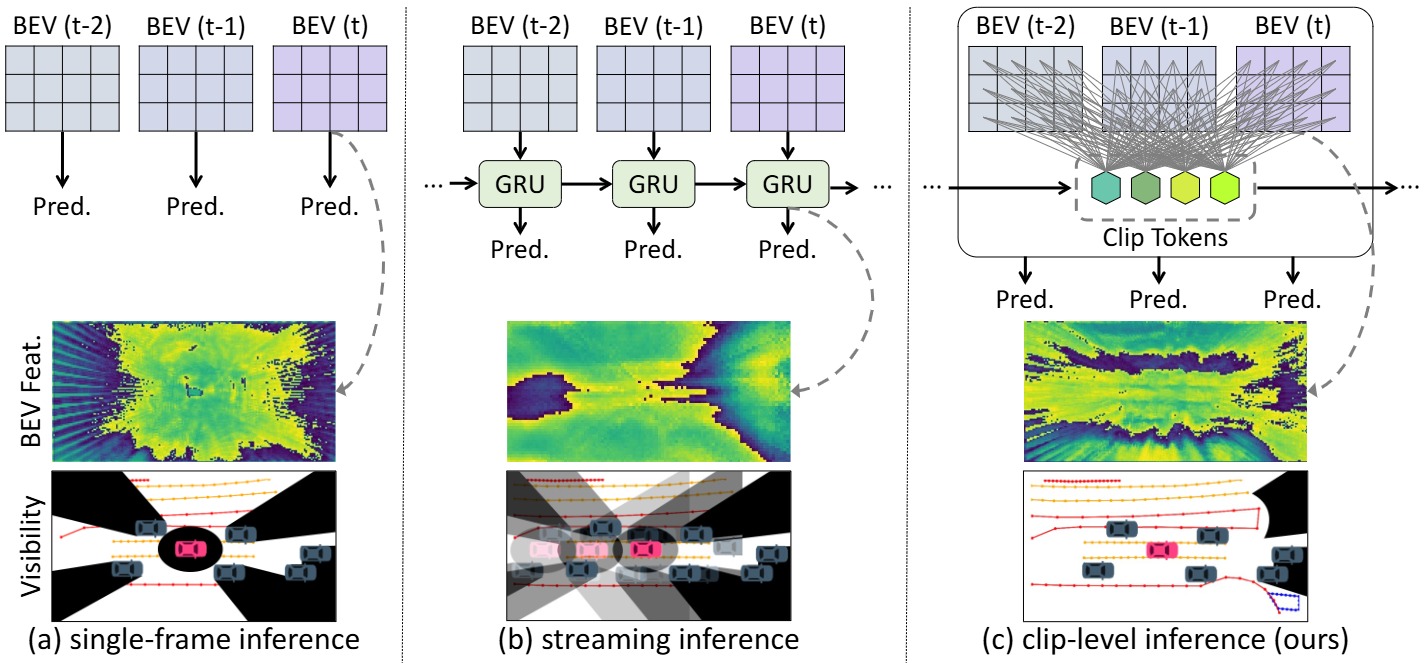
Predicting and constructing road geometric information (e.g., lane lines, road markers) is a crucial task for safe autonomous driving, while such static map elements can be repeatedly occluded by various dynamic objects on the road. Recent studies have shown significantly improved vectorized high-definition (HD) map construction performance, but there has been insufficient investigation of temporal information across adjacent input frames (i.e., clips), which may lead to inconsistent and suboptimal prediction results. To tackle this, we introduce a novel paradigm of clip-level vectorized HD map construction, MapUnveiler, which explicitly unveils the occluded map elements within a clip input by relating dense image representations with efficient clip tokens. Additionally, MapUnveiler associates inter-clip information through clip token propagation, effectively utilizing long- term temporal map information. MapUnveiler runs efficiently with the proposed clip-level pipeline by avoiding redundant computation with temporal stride while building a global map relationship. Our extensive experiments demonstrate that MapUnveiler achieves state-of-the-art performance on both the nuScenes and Argoverse2 benchmark datasets. We also showcase that MapUnveiler significantly outperforms state-of-the-art approaches in a challenging setting, achieving +10.7% mAP improvement in heavily occluded driving road scenes.

Our framework takes clip-level multi-view images and outputs clip-level vectorized HD maps. All components in the frame-level MapNet (i.e., Backbone, PV to BEV, Map Decoder) are adopted from MapTRv2. The frame-level MapNet extracts map queries and BEV features independently at each frame. MapUnveiler generates compact clip tokens that contain clip-level temporal map information and directly interact with dense BEV features. With the updated BEV features, we construct high-quality clip-level vectorized maps. The generated map tokens and clip tokens are then written to memory.
@inproceedings{kim2024unveiling,
title={Unveiling the Hidden: Online Vectorized HD Map Construction with Clip-Level Token Interaction and Propagation},
author={Kim, Nayeon and Seong, Hongje and Ji, Daehyun and Jang, Sujin},
booktitle={NeurIPS},
year={2024}
}